
Investigadores de la Universidad de Londres descubren la dinámica global del aprendizaje de representación en redes neuronales profundas

Las redes neuronales profundas (DNN) vienen en diferentes tamaños y estructuras. Se sabe que la arquitectura específica elegida junto con el conjunto de datos y el algoritmo de aprendizaje utilizados influyen en los patrones neuronales aprendidos. Actualmente, el principal desafío al que se enfrenta la teoría del aprendizaje profundo es la cuestión de la escalabilidad. Aunque existen soluciones exactas para la dinámica de aprendizaje de redes más simples, modificar una pequeña porción de la estructura de la red a menudo requiere grandes cambios en el análisis. Además, los modelos modernos son tan complejos que superan a las soluciones analíticas prácticas. Estos resultados consisten en modelos complejos de aprendizaje automático e incluso el cerebro, lo que plantea desafíos para el estudio teórico.
En este artículo, el primer trabajo relacionado son soluciones exactas sobre arquitecturas simples, ya que se ha avanzado mucho en el análisis teórico de redes neuronales lineales profundas, por ejemplo, se comprende bien el panorama de pérdidas y se obtienen soluciones exactas para condiciones iniciales específicas. . El siguiente enfoque relacionado es el kernel de sombra neuronal, donde la excepción notable en términos de soluciones globales es que proporciona soluciones exactas aplicables a una amplia gama de modelos. Lo siguiente son los sesgos implícitos en la técnica de regresión por pasos, donde se investiga la regresión por pasos como una fuente de rendimiento de generalización en redes neuronales profundas. El último método es la elasticidad local, donde el modelo exhibe esta propiedad si la actualización de un vector de características afecta de manera insignificante a diferentes vectores de características.
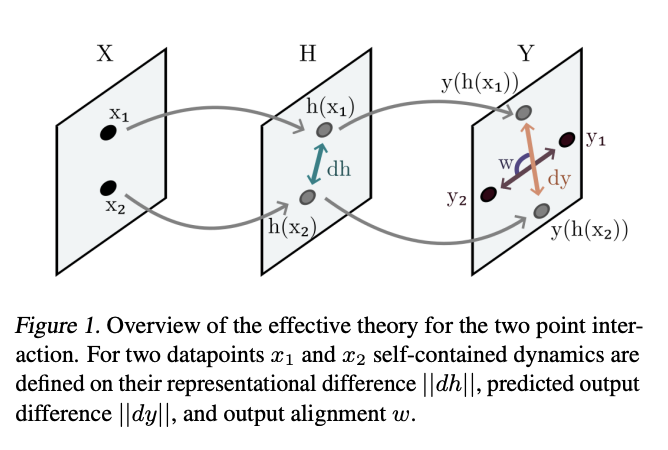
Investigadores del University College de Londres han propuesto un método para modelar el aprendizaje representacional de un extremo a otro, cuyo objetivo es explicar fenómenos comunes observados en los sistemas de aprendizaje. Se desarrolla una teoría eficiente para que dos puntos de datos similares interactúen entre sí durante el entrenamiento cuando la red neuronal es grande y compleja y, por lo tanto, no está severamente limitada por sus parámetros. Además, la existencia de un comportamiento universal en la dinámica del aprendizaje de representación se demuestra por el hecho de que la teoría derivada explica la dinámica de diferentes redes profundas con diferentes funciones de activación y arquitectura.
La teoría propuesta aborda la dinámica de la representación en “algunas clases intermedias H”. Dado que las redes neuronales profundas tienen muchas capas donde se pueden observar representaciones, surge la pregunta de cómo estas dinámicas dependen de la profundidad de la capa intermedia elegida. Para responder a esta pregunta, es necesario identificar los estratos sobre los cuales la teoría efectiva sigue siendo válida. Para que la aproximación lineal sea precisa, las representaciones deben comenzar muy juntas. Si los pesos iniciales son pequeños, el factor de ganancia de activación promedio para cada capa es una G constante, que es menor que 1. La distancia representacional inicial se muestra como una función de n escalas de profundidad:

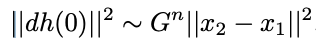
Esta función disminuye, por lo que la teoría debería ser más precisa en capas posteriores de la red.

Se espera que las tasas de aprendizaje efectivas difieran en diferentes capas ocultas. En la regresión de gradiente estándar, la actualización implica la suma de parámetros, por lo que los cambios son proporcionales a la cantidad de parámetros. En capas ocultas más profundas, el número de parámetros en el mapa del codificador aumenta, mientras que el número en el mapa del decodificador disminuye. Esto hace que la tasa de aprendizaje efectiva del codificador aumente con la profundidad y que el decodificador disminuya con la profundidad. Esta relación se mantiene para capas más profundas de la red donde la teoría es precisa; sin embargo, en capas anteriores, la tasa de aprendizaje efectiva para decodificar parece aumentar.
En resumen, investigadores de la Universidad de Londres han presentado una nueva teoría sobre cómo aprenden las redes neuronales, centrándose en patrones de aprendizaje comunes en diferentes arquitecturas. La teoría muestra que estas redes aprenden naturalmente representaciones estructuradas, especialmente cuando comienzan con pesos pequeños. En lugar de presentar esta teoría como un modelo universal final, los investigadores destacaron que el descenso de gradiente, el método principal utilizado para entrenar redes neuronales, puede respaldar aspectos del aprendizaje de representación. Sin embargo, este enfoque enfrenta desafíos cuando se aplica a conjuntos de datos más grandes, y se necesita más investigación para abordar de manera efectiva estas complejidades y manejar datos más complejos.
Comprobar el papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. No olvides seguirnos en Gorjeo.
Únete a nosotros canal de telegramas Y LinkedInctransmisión exterior.
Si te gusta nuestro trabajo, te encantará nuestro trabajo. las noticias..
No olvides unirte a nosotros SubReddit de 46k+ ML


Sajjad Ansari es un estudiante de último año de pregrado del Instituto de Tecnología de Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA con un enfoque en comprender el impacto y las implicaciones de las tecnologías de IA en el mundo real. Su objetivo es formular conceptos complejos de IA de una manera clara y accesible.

“Defensor de la Web. Geek de la comida galardonado. Incapaz de escribir con guantes de boxeo puestos. Apasionado jugador”.